

OpenAI DevDay 2024 - Novidades
O que a sua empresa pode aproveitar destas novidades


Ontem - 01/10/2024 - a OpenAI lançou 4 novidades nos seus produtos que com certeza serão úteis para aqueles que utilizam seus serviços. Vamos dar um overview em cada uma delas:
Realtime API - API de tempo real

Agora você pode criar um assistente de voz via API usando o módulo de voz mais avançado da OpenAI - quele que você conversa e ele responde sem delay. Ele suporta até seis tipos de voz e múltiplas línguas.
Como que funciona?
Previously, to create a similar voice assistant experience, developers had to transcribe audio with an automatic speech recognition model like Whisper, pass the text to a text model for inference or reasoning, and then play the model’s output using a text-to-speech(opens in a new window) model.
Como o texto acima explica, antigamente você tinha que usar o Whisper para transcrever o áudio, e só depois usar o modelo do chatGPT para responder. Agora não - ele vai fazer tudo de forma simultânea, entendendo o que está sendo dito, pesquisado as respostas e falando de volta.
Talvez o que tem de mais interessante é que esta API vai suporte o function calling, que é quando você cria uma função para ele fazer alguma atividade requisitada, como por exemplo buscar algum dado de outra API para responder sua pergunta.
Alguns cenários úteis possíveis:
Atendente de marketing via voz: qualquer pergunta que a pessoa fizer, não vai ter aquele delay de uns 5 segundos para responder, será praticamente imediato, como um pessoa normal. Qualquer pergunta que a pessoa fizer sobre o produto, ela poderá consultar base de dados para responder, o que pode ser muitíssimo interessante. Claro que quando ela for consultar dados externos, provavelmente vai demorar um pouco mais.
Secretária pessoal eletrônica: imagina você ter um aplicativo que você conversa com uma secretária eletrônica que tem acesso a um monta de funções que você pode especificar no seu aplicativo. Seria sensacional para marcar reuniões, mandar emails, inserir informações em banco de dados, etc.
Suporte: um suporte via voz, com retorno imediato da pergunta e como deve proceder será o próximo passo que os aplicativos tentarão implementar.
Valores:
The Realtime API uses both text tokens and audio tokens. Text input tokens are priced at $5 per 1M and $20 per 1M output tokens. Audio input is priced at $100 per 1M tokens and output is $200 per 1M tokens. This equates to approximately $0.06 per minute of audio input and $0.24 per minute of audio output. Audio in the Chat Completions API will be the same price.
De acordo com o texto acima, pode chegar a custar por volta de $0.30 por minuto. Com certeza ainda está caro, mas já dá para fazer alguns teste. Geralmente a OpenIA começa com um preço mais elevado e, em poucos meses, os custos diminuem muito. Acredito que será o mesmo com esta API.
Fine-tuning API para visão
Este módulo vai permitir você fazer fine-tuning de imagem, e não apenas de texto como era antes. Isso é interessante porque você poderá ter uma imagem treinada especificamente para suas necessidades, e o modelo vai entender muito melhor o que é esta imagem e as informações que contém nela.
Como que funciona?
Você faz o upload de pelo menos 100 imagens das que você quer que ele faça o fine-tuning, e ele treina naquelas imagens. Veja um exemplo de como ficaria o JSON:
{
"messages": [
{ "role": "system", "content": "You are an assistant that identifies uncommon cheeses." },
{ "role": "user", "content": "What is this cheese?" },
{ "role": "user", "content": [
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/3/36/Danbo_Cheese.jpg"
}
}
]
},
{ "role": "assistant", "content": "Danbo" }
]
}Alguns cenários úteis possíveis:
Uma empresa chamada Automat que faz bots para clicar em botões e fazer automações (chamados RPAs), usou esta API para melhorar em 272% a performance dos seus bots. Impressionante!
Outra empresa chamada Coframe também usou esta API para melhorar o processo de análise de websites da sua empresa, e dar feedback para seus usuários
Valores:
We’re offering 1M training tokens per day for free through October 31, 2024 to fine-tune GPT-4o with images. After October 31, 2024, GPT-4o fine-tuning training will cost $25 per 1M tokens and inference will cost $3.75 per 1M input tokens and $15 per 1M output tokens. Image inputs are first tokenized based on image size, and then priced at the same per-token rate as text inputs. More details can be found on the API Pricing page.
De acordo com o texto acima, será cobrado $25 por 1 milhão de tokens. Imagens são transformadas em números primeiro - chamados de tokens - e depois processadas. Isso é que dá o custo do processo. No final, para treinar 100 imagens do tamanho de uma folha A4, com 500 a 700 palavras, provavelmente daria menos de $51.
Cacheamento de Prompt via API

Quando você utiliza o mesmo prompt várias vezes para fazer a mesma tarefa numa IA, agora a IA fará o cache destas informações, reduzindo seus custos em até 50%.
Como que funciona?
Você não precisa de nenhuma ação - os prompts recentes serão cacheados automaticamente, e você terá um custo reduzido se reutilizá-los de forma automática.
Importante notar que os caches serão limpos depois de 5-10 minutos, ou seja, é apenas para tarefas repetitivas naquele mesmo momento.
Valores:
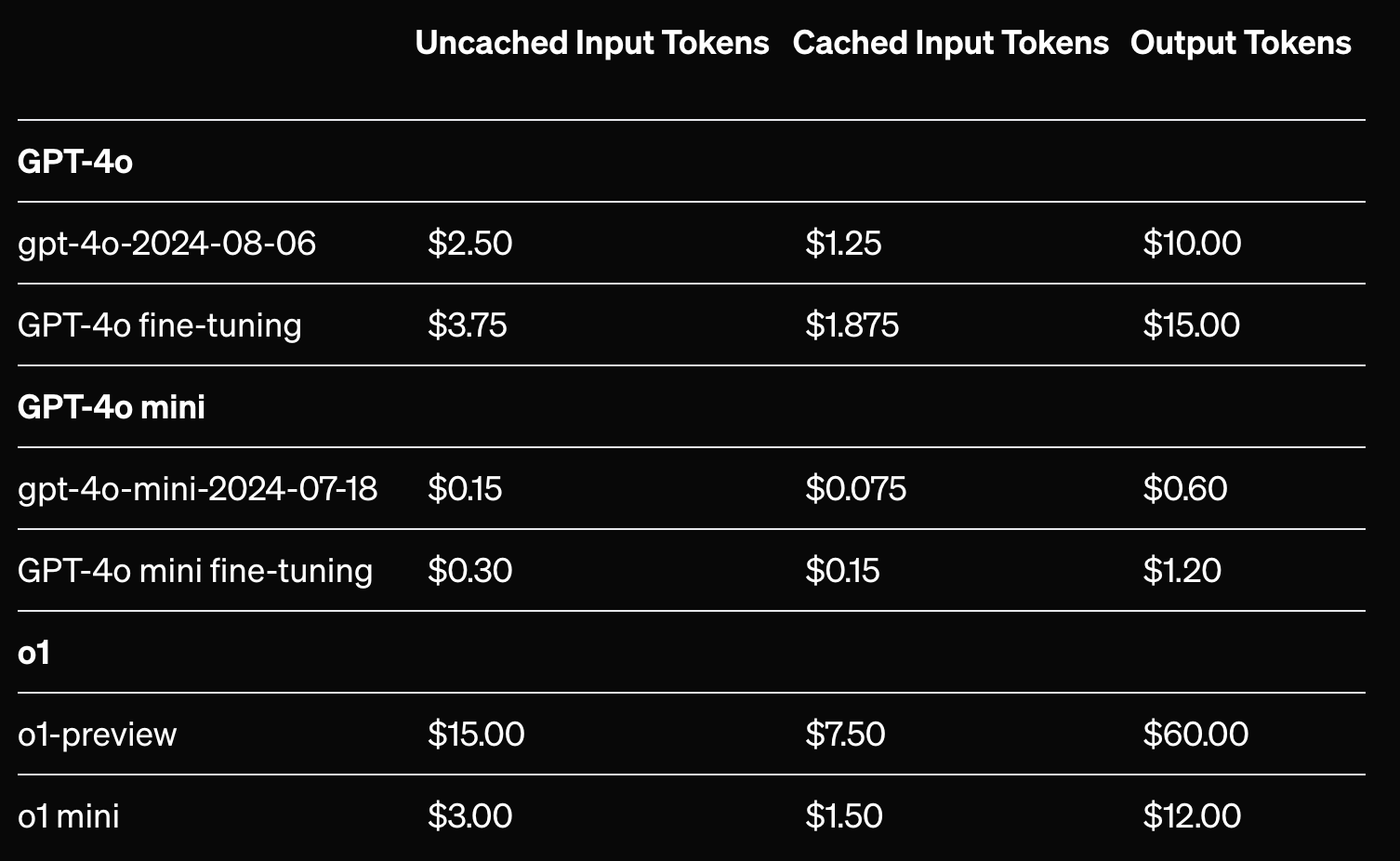
Como você pode ver na imagem, os valores podem ser bem menores se você você fizer requisições que utilizem o prompt cacheado.
Modelo de Destilação via API

Agora você poderá fazer fine-tuning de um modelo pequeno como o GPT-4o mini através dos resultados dos modelos mais recentes como o1-preview e GPT-4o.
This lets developers easily use the outputs of frontier models like o1-preview and GPT-4o to fine-tune and improve the performance of more cost-efficient models like GPT-4o mini.
Aparentemente este é um processo que a OpenAI está fazendo com seus próprios modelos - usando modelos mais poderosos para treinar modelos menos poderosos.
Teoricamente você não precisaria de um novo conhecimento gerado por um ser humano. A própria IA gera o conhecimento para o treinamento dela mesma!
Como que funciona?
O processo de distilação de modelo envolve treinar modelos menores (como o GPT-4o mini) usando saídas de modelos maiores e mais avançados (como o GPT-4o). Primeiro, as saídas do modelo avançado são capturadas e armazenadas como conjuntos de dados. Esses dados são usados para ajustar o modelo menor, ajudando-o a imitar o desempenho do modelo maior de forma eficiente. Em seguida, são feitas avaliações integradas para medir a eficácia do modelo ajustado. Tudo isso ocorre dentro da plataforma da OpenAI, facilitando a automatização e o controle do processo de treinamento e avaliação.2
Valores:
Até 31 de Outubro de 2024 você pode treinar gratuitamente até 2M de tokens. Depois desta data, os preços serão os mesmos de você fazer um fin-tuning.
Considerações finais
A OpenAI está se mostrando com uma capacidade impressionante de inovação com estas novas funcionalidades - e o melhor: para desenvolvedores. Porque isso é tão importante? Pelo simples motivo de que são os desenvolvedores que criarão novos projetos, novas economias, através do uso destas APIs.
Portanto vale a pena você checar onde poderia incluir isto no processo de utilização de IA na sua empresa ou negócio.
Esta é apenas uma estimativa que fiz usando o chatGPT, onde ele considerou uma imagem retirada de um PDF contendo 500 a 700 palavras. Leve em conta que este valor pode ser bem maior se suas imagens forem com mais informação por página.
É importante notar que a explicação exata de como este processo funciona não caberia no escopo deste artigo. Portanto, visite a página da OpenAI para um melhor entendimento